涂莹(1972-),女,陕西西安人,高级工程师,从事营销信息化、 “互联网+营销服务”智能互动服务创新体系研究与实践工作;
0 引言
2013年以来,我国先后发布了《国务院关于印发大气污染防治行动计划的通知》(国发[2013]37号)和《能源发展战略行动计划(2014—2020年)》(国办发[2014]31号)等文件,国家层面对大气污染的防治越来越重视。根据《关于推进电能替代的指导意见》(发改能源[2016]1054号)文件,目前大气污染的主要根源在于需求侧大量的散烧煤与燃油消费[1],这将造成严重的雾霾。
近十几年来,随着科技与技术的进步,生产机器设备不断更新换代,企业生产和供电越来越紧密,国网浙江省电力有限公司在经营服务中积累了海量的企业用能数据,为挖掘企业电能替代前后的用能数据提供了可能 [2]。
另一方面,目前供电企业在推进电能替代工作时,采用传统的逐户排查方式,排查效率低下,实际工作成功率低;而电能替代涉及的设备改造、成本核算、政策调整等问题,对工作人员的专业能力提出了更高要求[3-4]。企业需要探索新方法、研究新技术,深入分析电能替代企业的特征,利用大数据技术精准定位潜力用户群体,提升企业开展电能替代工作的效率和专业化水平[5]。
电能替代潜力企业分析以用能设备为切入点,分析高能耗且使用非电能源较多的设备所处行业,定位电能替代工作重点挖掘的行业,通过分析设备能耗、生产时段、用电功率等信息寻找企业电能替代改造前后的用电差异,确定模型输入指标,以此为依据构建模型[6]。
1 电能替代研究现状
国内外学者已对电能替代做了大量研究。赵会茹等[7]从国家宏观层面阐述了电能替代在当前国家经济、环境发展战略中的机遇与挑战,并进行了环境和经济效益的量化评估;Diyar,Mehmet等[8]从能源供给侧出发,系统地分析了土耳其从以煤电为主向水电、核电、风电等清洁能源转变的可能性、可执行性,同时运用灰度算法预测电能替代的经济效益。此外,在对用户用电负荷特性进行分类研究的基础上,李美娜等[9]提出了模糊C-均值聚类算法,并通过基于聚类方法评价指标,选取合适的聚类数目。
本文在用户分类上采用了K-means均值分类算法,在确定聚类数目时综合考虑可替代设备、行业的生产特性因素。在对企业电能替代潜力预测方面,本文从电能需求侧供给角度出发,采用大数据挖掘技术,运用有监督的协同过滤学习算法,实现对电能替代潜力用户的判别[10-11],提升供电企业电能替代工作的专业化和信息化水平。
2 重点行业分析及行业聚类
2.1 重点行业分析
根据《国民经济行业分类》(GB/T4754—2002),我国行业共分20个门类913个小类,不同行业的产品、生产时段、生产设备等都存在较大差异,假如对所有细分行业分门别类地分析建模,不仅耗时耗力,且很可能会存在因部分行业目标样本过少导致模型结果不显著的问题[12]。
本文基于细分行业各类能源使用的占比、可替代设备集中行业两方面对细分行业进行筛选,根据浙江省能源结构[1],对能耗较高、非电能源占比较高且具备可替代设备的行业进行重点分析。
2014年工业各行业能源消费总量及构成如
 图1
2014年工业各行业能源消费总量及构成
Fig.1
Total energy consumption and composition of industrial sectors in 2014
图1
2014年工业各行业能源消费总量及构成
Fig.1
Total energy consumption and composition of industrial sectors in 2014
从可替代设备所应用的行业角度看,根据《关于推进电能替代的指导意见》,当前主要可替代设备有窑炉、锅炉、采暖等,各类替代设备主要应用行业见
结合上述分析,并将部分生产特征相似的行业归纳合并,初步确定20个待分析行业,电能替代重点行业见
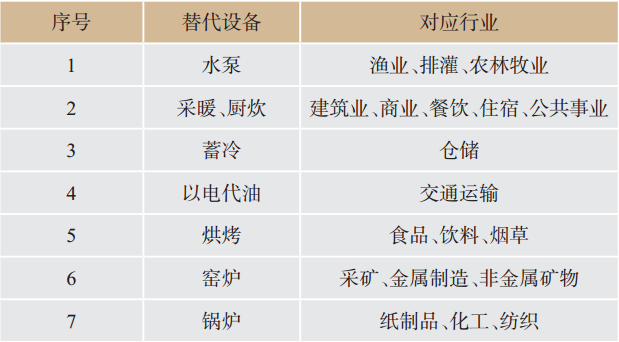 表1
各类替代设备主要应用行业
Tab.1
Major application industries of alternative equipments
表1
各类替代设备主要应用行业
Tab.1
Major application industries of alternative equipments
 表2
电能替代重点行业
Tab.2
Key industries of power substitution
表2
电能替代重点行业
Tab.2
Key industries of power substitution
2.2 行业聚类分析及类别选择
对各行业分时用电负荷进行统计描述分析,各行业96点日负荷曲线分布如
对各行业96点负荷变量采用K-means算法进行聚类分析,各行业聚类结果见
 图2
各行业96点日负荷曲线分布
Fig.2
Distribution curves of load curves with 96 points per day in different industries
图2
各行业96点日负荷曲线分布
Fig.2
Distribution curves of load curves with 96 points per day in different industries
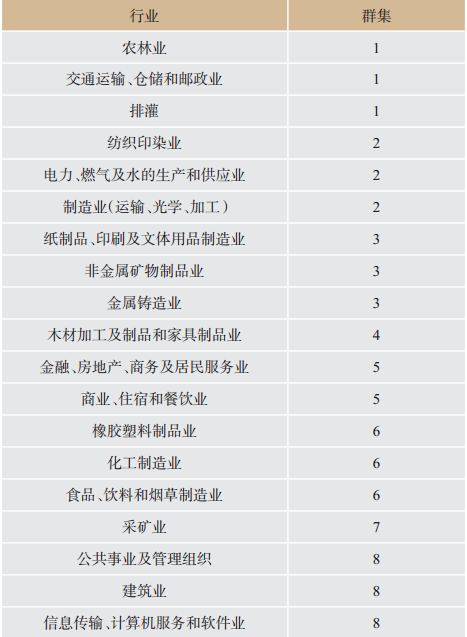 表3
各行业聚类结果
Tab.3
Results of cluster analysis in different industries
表3
各行业聚类结果
Tab.3
Results of cluster analysis in different industries
另一方面,通过数据统计,部分类群对应的已完成电能替代改造的样本数过少,以此构建的模型解释能力一般较弱(见
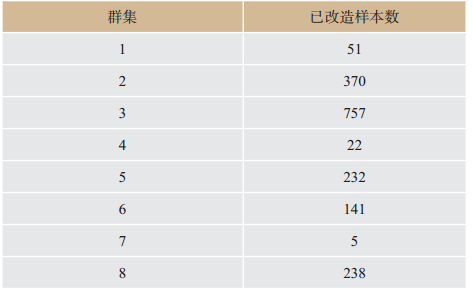 表4
各类群已改造样本数
Tab.4
The number of transformed samples in each group
表4
各类群已改造样本数
Tab.4
The number of transformed samples in each group
3 企业电能替代前后用电特征变化研究
企业用电的用途主要分3类:日常照明、机械设备运作和供能加热。在电能替代中,以供能加热设备为例,如窑炉替换成中频炉、燃煤锅炉替换成电锅炉,天然气供热替换成电供热等,这类加热设备普遍存在功率大、能耗高等特点,此类设备耗电量一般占企业总用电量的30%~60%,用电时段呈现出阶段性特征。这种阶段性高耗电的特征在企业用电负荷数据上会出现明显的波峰,因此通过比对用电负荷的差异,能够精准地识别出使用非电能源的企业[14]。
本文选取了金属铸造(五金、电器铸造业)和公共事业(高等院校)两个典型行业进行电能替代改造前后的日负荷曲线分析[15]。改造前后负荷曲线变化如
通过大量样本观测发现,不同行业替代设备改造前后的日负荷曲线变化差异较大,而在同行业中这种差异十分显著,这为通过对比目标样本改造前的日负荷曲线与待预测样本的日负荷曲线的相似度提供了可能。
 图3
典型行业电能替代改造前后日负荷曲线变化
Fig.3
Daily load curve changes before and after replacement of electric energy in typical industries
图3
典型行业电能替代改造前后日负荷曲线变化
Fig.3
Daily load curve changes before and after replacement of electric energy in typical industries
4 基于协同过滤算法的电能替代用户判别模型
4.1 算法选择
目前对曲线相似度的计算主要是运用动态时间归整(Dynamic Time Warping,DTW)算法,但该算法需要大量的路径并对这些路径节点进行匹配计算,而日负荷96点曲线的节点数量过少,容易造成计算结果识别率不高的问题,基于DTW算法的公共事业行业的各类日负荷曲线如
不佳。
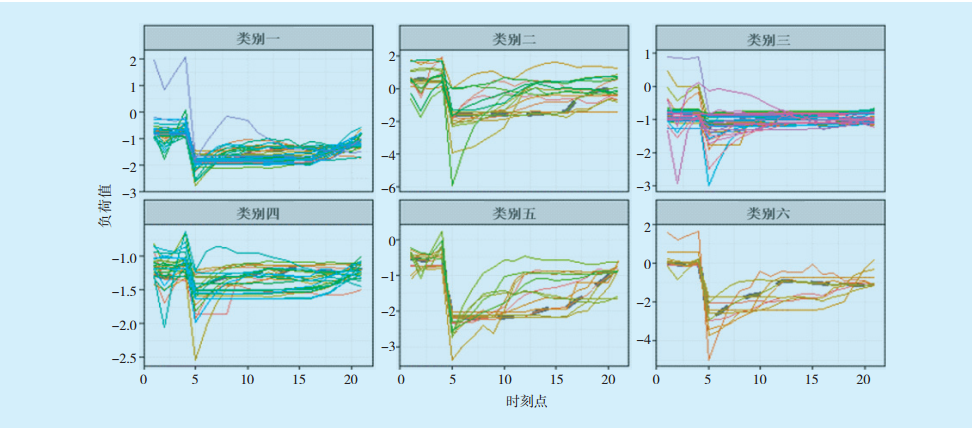 图4
基于DTW算法的公共事业行业的各类日负荷曲线
Fig.4
Daily load curve of public utilities industry based on DTW algorithm
图4
基于DTW算法的公共事业行业的各类日负荷曲线
Fig.4
Daily load curve of public utilities industry based on DTW algorithm
本文通过处理96点日负荷,计算2个企业间的相似度。通过将目标样本改造前曲线与待预测样本曲线的相似度对比,找出各类群与目标样本改造前曲线相似的企业,作为模型结果潜力用户的输出。模型思路如
 图5
模型思路
Fig.5
Thinking of model
图5
模型思路
Fig.5
Thinking of model
协同过滤算法在电商领域有着广泛的应用,它是一种商品推荐算法,用于给品味相似的用户推荐相关的商品。
在本文中,将商品替换为96点日负荷采集点,采用皮尔逊相关系数[10]计算两个用户间的相似度。假设用户A在负荷点i的得分为ra,i,用户A所有负荷点平均得分为ra,用户A的负荷点得分集合为Ia,用户A和用户B负荷点得分集合为Iab,则用户A、B的Pearson相似度为:
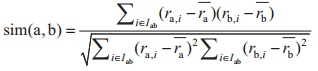
式中,ra,i为用户A在第i个负荷时刻的负荷值,ra为用户A的负荷均值,rb,i和rb同理。由于本文项目中没有缺失的负荷点,因此无需对某个负荷点的数值做预测,因此仅需要计算用户间的sim值即可。
在上述公式中,用户A即为目标样本,用户B为待预测样本。假设用户集为{a1,a2,…,an},每个用户有96个负荷点的维度,K-means最终聚类集为S={S1,S2,…,Sk}, 其中k≤n。若使簇内平方和最
小,有:
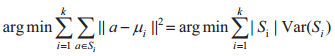
式中,μ为每个簇S的平均值,上式等同于最小化成对的平方偏差:

式中d为维度,d∈(1,2,…,96),在确立目标样本簇后,计算每个簇与对应类群待预测企业用户与各类簇的相似度。
4.2 模型验证
对本文模型共计输入目标样本1 597个,待预测样本281 648个。按7:3的比例,根据聚类分群实行分层抽样法,对目标样本进行分层工作,各类群样本分布及分层抽样结果见
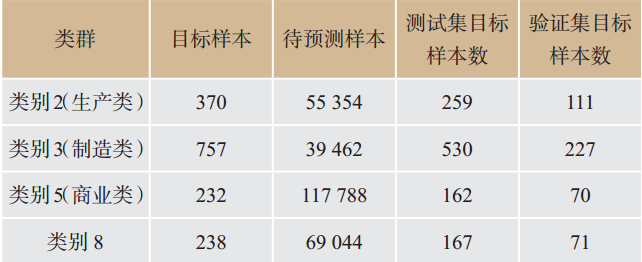 表5
各类群样本分布及分层抽样结果
Tab.5
Sample distribution and stratified sampling results of various groups
表5
各类群样本分布及分层抽样结果
Tab.5
Sample distribution and stratified sampling results of various groups
协同过滤算法属于关联算法,因此在模型验证上沿用传统模型验证的思维,即检验目标样本对待预测样本识别的准确性和稳定性[16],用测试集与验证集内的目标样本分别计算待预测样本的相
似度。
至此,对协同过滤算法的验证问题将转化为两独立样本的差异性检验问题,T检验结果P值为0.20,远大于0.05,接受原假设,说明通过测试集与验证集得到的结果并无太大差异。
在此,引入其他预测模型算法,并对比在此项目中与协同过滤算法的优劣。各模型算法成效比较(以Cluster3为例)见
 表6
各模型算法成效比较(以Cluster3为例)
Tab.6
Comparison of the effectiveness of each model algorithm
表6
各模型算法成效比较(以Cluster3为例)
Tab.6
Comparison of the effectiveness of each model algorithm
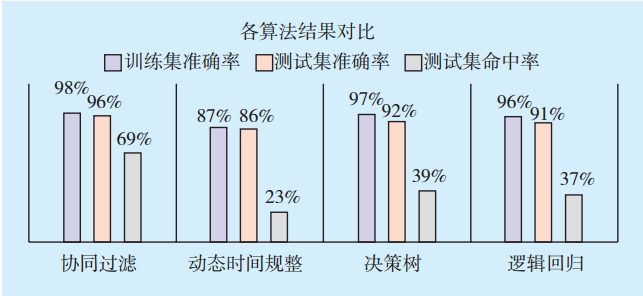 图6
各模型算法成效比较(以Cluster3为例)
Fig.6
Comparison of the effectiveness of each model algorithm(Taking Cluster3 as an example)
图6
各模型算法成效比较(以Cluster3为例)
Fig.6
Comparison of the effectiveness of each model algorithm(Taking Cluster3 as an example)
各类群模型命中率见
 表7
各类群模型命中率
Tab.7
Comparison of hit rate of different group models
表7
各类群模型命中率
Tab.7
Comparison of hit rate of different group models
5 模型实际应用及成效
本文对应项目于2016年10月初步完成模型构建并应用于系统平台,对浙江省嘉兴市、绍兴市两地先后进行了3次排查,在此过程中,对输入模型的目标样本作了更为精确的筛选,剔除了部分干扰样本,并且更改了负荷曲线的提取周期,减少因为季度因素变化、企业经营设备调整等因素造成的结果偏差。与最初的盲排走访1.5%的命中率相比,摸排效率在不同行业中均得到了大幅提升。
6 结语
本文在对企业用能与生产特征关系分析的基础上,运用大数据挖掘技术,提出了精准定位潜在电能替代用户的具体方法。并深入分析了企业用电和其他用能的关系,创新性地将协同过滤算法引入电能替代分析模型中,分析用户用能特征与用电结构化数据之间的对应关系,最后运用历史数据及实践结果验证了模型的实效性和真实性,是协同过滤算法在电力领域应用的一次成功尝试,极大地提高了电能替代潜力用户挖掘的效率,推动全行业电能替代工作的顺利开展。
(编辑:邹海彬)
参考文献
[1]
[2]
[3]
[4]
[5]
[6]
[7]
[8]
[9]
[10]
[11]
[12]
[13]
[14]
[15]
[16]
-

-
刘强(1974-),男,山东烟台人,高级工程师,从事电力营销管理工作;
-
王庆娟(1988-),女,吉林白山人,工程师,从事渠道运营、渠道数据技术相关工作;
-
陈烨洪(1985-),男,浙江绍兴人,工程师,从事电网规划设计及运行维护工作。